Airflow¶
This part presents an overview of Airflow tool for educational purposes.
- Name: Maxime Beauchemin
- Background: Ex-Airbnb and ex-Facebook engineer
- Contribution: Developed Apache Airflow at Airbnb to manage complex workflows
-
Data Engineering
- ETL/ELT Pipelines: Extract, Transform, Load (Extract, Load, Transform) data from various sources.
- Data Processing: Automate data cleaning, transformation, and loading processes.
-
Machine Learning
- MLOps: Orchestrate the entire machine learning lifecycle, including data preparation, model training, and deployment2.
- Model Training: Schedule and monitor machine learning model training jobs.
-
Operational Analytics
- Automated Reporting: Generate and distribute reports on a scheduled basis.
- Real-time Analytics: Process and analyze data in real-time for timely insights.
-
DevOps
- Infrastructure Management: Manage infrastructure provisioning and de-provisioning.
- Backup and Restore: Schedule regular backups and automate restore processes.
-
**Custom Workflows
- Ad Hoc Tasks: Run one-off tasks that are not tied to a schedule.
- Event-Driven Workflows: Trigger tasks based on external events, such as file uploads or API calls5.
Introduction to Apache Airflow¶
Apache Airflow is—a platform to programmatically author, schedule, and monitor workflows.
Use Cases: Highlight common use cases, such as ETL processes, data pipeline automation, and machine learning workflows.
Key Points¶
- Open-source workflow management tool
- Focus on scalability and flexibility
- Suitable for batch-oriented workloads
Main Characteristics of Apache Airflow¶
Directed Acyclic Graphs (DAGs)¶
workflows are defined as DAGs, ensuring tasks are executed in a specific order without cycles.
Task Instances¶
Discuss how each task within a DAG is an instance, allowing for granular monitoring and control.
Scheduler¶
The Airflow scheduler is essential for managing the execution of tasks in a workflow, ensuring that tasks run at the specified intervals and in the correct order1. Its ability to handle dependencies, manage concurrency, and handle failures makes it a powerful tool for orchestrating complex data pipelines.
Monitoring DAGs and Tasks¶
The scheduler continuously monitors all Directed Acyclic Graphs (DAGs) and their tasks. It keeps track of the state of each task and DAG, ensuring that tasks are executed in the correct order based on their dependencies.
Scheduling Tasks¶
The scheduler uses the schedule_interval parameter defined in each DAG to determine when to run tasks. This parameter can be a cron expression or a timedelta object.
For example, a DAG with a schedule_interval of '@daily' will run once a day at midnight.
Triggering Task Runs¶
When the scheduler determines that a task should be run (based on the schedule_interval and task dependencies), it triggers the task instance. This involves creating a DAG run and scheduling the tasks within that run.
Triggering Task Runs¶
When the scheduler determines that a task should be run (based on the schedule_interval and task dependencies), it triggers the task instance. This involves creating a DAG run and scheduling the tasks within that run.
Handling Dependencies¶
The scheduler ensures that tasks are executed only when their dependencies have been met. This means that if Task B depends on Task A, Task B will not start until Task A has successfully completed.
Managing Concurrency¶
The scheduler enforces concurrency limits to prevent overloading the system. It checks the number of currently running tasks and ensures that the number of new tasks scheduled does not exceed the configured limits.
Handling Failures and Retries¶
If a task fails, the scheduler can automatically retry the task based on the retry configuration specified in the DAG. It manages retries and ensures that failed tasks are retried according to the defined retry policy.
Continuous Operation¶
The scheduler runs as a persistent service in a production environment. It continuously checks for new DAG runs and schedules tasks as needed. To start the scheduler, you simply run the command airflow scheduler.
Backfilling and Catchup¶
Airflow can backfill data by running tasks for past intervals that have not been executed. This is useful for populating historical data. The scheduler can also catch up on missed runs if the system was down or tasks were delayed.
Executor Types¶
In Apache Airflow, the Executor is responsible for managing how and where tasks are run. Different executors are designed to cater to different scalability and deployment needs.
Here are the main types of executors in Airflow:
SequentialExecutor¶
The simplest executor, which runs tasks sequentially, one at a time. Use Case: Suitable for development and testing environments where only one task needs to be run at a time.
Pros:¶
- Easy to set up and use.
- Minimal resource requirements.
Cons:¶
Not suitable for production or environments that require parallel task execution.
LocalExecutor¶
Executes tasks in parallel using multiple worker processes on a single machine. Use Case: Suitable for small to medium-scale deployments where parallelism is required but resources are limited to a single machine.
Pros:¶
- Easy to set up.
- Supports parallel execution.
Cons:¶
- Limited by the resources of a single machine.
- May not scale well for very large workloads.
CeleryExecutor¶
Uses Celery to distribute task execution across multiple worker nodes. This executor is suitable for larger-scale, distributed environments. Use Case: Ideal for production environments that need to scale out task execution across multiple machines.
Pros:¶
- Highly scalable and flexible.
- Supports distributed execution and fault tolerance.
Cons:¶
- Requires additional components like a message broker (RabbitMQ, Redis) and a backend database (e.g., PostgreSQL, MySQL).
- More complex to set up and maintain compared to simpler executors.
KubernetesExecutor¶
Runs each task in a separate Kubernetes pod, leveraging Kubernetes for scalability and orchestration. Use Case: Best suited for environments that already use Kubernetes for container orchestration and need to scale Airflow tasks dynamically.
Pros:¶
- Dynamic scaling based on Kubernetes.
- Isolation of tasks in separate pods enhances security and resource management.
Cons:¶
- Requires a Kubernetes cluster.
- More complex to configure and manage.
DaskExecutor¶
Dask is a parallel computing library to execute tasks. DaskExecutor is designed for distributed computing environments. Use Case: Suitable for environments that use Dask for parallel processing and need to integrate Airflow with Dask’s distributed computing capabilities.
Pros:¶
- Leverages Dask's distributed computing power.
- Can scale out tasks across multiple workers.
Cons:¶
- Requires knowledge of Dask.
- May be more complex to set up compared to LocalExecutor or SequentialExecutor.
Key Point¶
Each executor in Airflow is designed to address different needs and scale levels. Here’s a quick comparison to help you choose the right executor for your use case:
- SequentialExecutor: Best for development and testing.
- LocalExecutor: Good for small to medium-scale deployments on a single machine.
- CeleryExecutor: Ideal for large-scale, distributed production environments.
- KubernetesExecutor: Perfect for Kubernetes-based environments needing dynamic scaling.
- DaskExecutor: Suitable for integrating with Dask for distributed computing.
Choosing the right executor depends on your specific requirements, available resources, and scalability needs.
Architecture of Apache Airflow¶
Components Overview¶
- Scheduler: Manages task execution
- Executor: Executes tasks
- Worker: Executes the tasks, can be scaled horizontally
- Metadata Database: Stores state information of DAGs and tasks
- Web Server: Provides a UI for monitoring and managing workflows
Key Points¶
- Centralized architecture for monitoring and control
- Scalable components to handle large workloads
- Integration with various backends and services
Detailed Architectural Breakdown¶
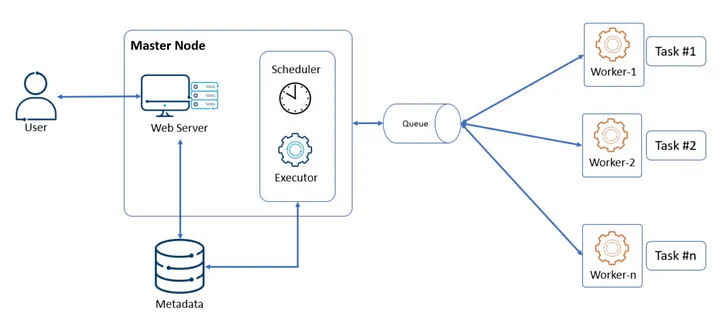 source : Bageshwar Kumar
source : Bageshwar Kumar
Scheduler:¶
The scheduler is the heart of Airflow, responsible for scheduling the execution of tasks. Here’s how it works:
-
Monitoring: Continuously monitors DAGs (Directed Acyclic Graphs) and their associated tasks.
-
Task Triggering: Determines when tasks should be run based on their schedule_interval and dependencies.
-
Concurrency Management: Manages the execution concurrency to ensure system stability.
-
Fault Tolerance: Handles task retries and failures, ensuring tasks are re-executed as configured.
The scheduler is crucial for ensuring that tasks are executed at the right time and in the correct order.
Executor¶
The executor is responsible for executing the tasks scheduled by the scheduler. Airflow supports several types of executors, each designed for different use cases (see Executor).
Workers¶
Workers are the entities that execute the tasks assigned by the executor. Depending on the executor type:
-
LocalExecutor Workers: Use local processes to run tasks.
-
CeleryExecutor Workers: Distributed across multiple nodes, each running Celery workers.
-
KubernetesExecutor Workers: Use Kubernetes pods to run tasks.
Workers handle the actual execution of tasks, ensuring that they are completed successfully.
Metadata Database¶
The metadata database stores all the state and configuration information for Airflow, including:
-
DAG Definitions: The structure and schedule of DAGs.
-
Task Instances: The state of each task instance (e.g., success, failure, running).
-
Logs and Metrics: Detailed logs of task executions and system metrics.
-
User Information: User roles and access permissions.
Common databases used include PostgreSQL and MySQL. The metadata database is crucial for maintaining the state and history of workflows.
Web Server¶
The web server provides a user interface for monitoring and managing Airflow workflows. Key features include:
-
DAG Visualization: Visual representation of DAGs and their task dependencies.
-
Task Monitoring: Real-time status of task instances, including logs and execution details.
-
Triggering and Pausing DAGs: Ability to manually trigger or pause DAGs.
-
Access Control: User authentication and role-based access control.
The web server is built using Flask and offers an intuitive interface for interacting with Airflow.
Key Points¶
- DAG: User defines a DAG with its tasks and schedules it using a Python script.
- Scheduler: Heart of the Airflow, triggering task execution
- Executor: Executes tasks using different backend options
- Workers: Scalable nodes that carry out tasks
- Metadata Database: Maintains state and scheduling info
- Web Server: UI for workflow management
Integration and Extensions¶
Apache Airflow is highly extensible and integrates seamlessly with various tools and libraries, making it a powerful platform for orchestrating complex workflows.
Plugins¶
Plugins in Airflow allow you to extend its core functionality by adding custom hooks, operators, sensors, executors, web views, and more. Plugins enable you to tailor Airflow to meet specific requirements of your workflows.
Creating a Plugin¶
Creating a plugin is achieve by defining a Python class that inherits from AirflowPlugin and adding custom components to it.
from airflow.plugins_manager import AirflowPlugin
from airflow.operators.dummy_operator import DummyOperator
class MyCustomPlugin(AirflowPlugin):
name = "my_custom_plugin"
operators = [DummyOperator]
Custom Hooks and Operators¶
Custom hooks can interact with external systems and custom operators to define specific tasks.
from airflow.models import BaseOperator
from airflow.utils.decorators import apply_defaults
class MyCustomOperator(BaseOperator):
@apply_defaults
def __init__(self, my_param, *args, **kwargs):
super(MyCustomOperator, self).__init__(*args, **kwargs)
self.my_param = my_param
def execute(self, context):
self.log.info(f"Running with parameter: {self.my_param}")
Operators:¶
Operators are building blocks of workflows in Airflow. Each operator performs a specific task, such as executing a Python function, running a Bash script, or transferring data between systems.
-
Types of Operators: Airflow comes with a variety of built-in operators, such as:
-
BashOperator: Runs a bash command.
-
PythonOperator: Executes a Python callable.
-
EmailOperator: Sends an email.
-
SqlOperator: Executes an SQL command.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def my_function():
print("Hello from PythonOperator")
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1)
}
with DAG('my_dag', default_args=default_args, schedule_interval='@daily') as dag:
task = PythonOperator(
task_id='my_python_task',
python_callable=my_function
)
You can extend the BaseOperator class to create custom operators that cater to specific needs.
Sensors¶
Sensors are a special type of operator that waits for a certain condition to be met before proceeding. They are useful for tasks that depend on external events or conditions.
-
Built-in Sensors: Airflow includes several built-in sensors, such as:
-
ExternalTaskSensor: Waits for a task in another DAG to complete.
-
FileSensor: Waits for a file to appear in a specified location.
-
HttpSensor: Waits for an HTTP endpoint to return a certain status.
from airflow import DAG
from airflow.operators.sensors import FileSensor
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1)
}
with DAG('my_sensor_dag', default_args=default_args, schedule_interval='@daily') as dag:
wait_for_file = FileSensor(
task_id='wait_for_file',
filepath='/path/to/file',
poke_interval=30, # Check every 30 seconds
)
custom sensors by extending the BaseSensorOperator class and implementing the poke method. The poke method is called repeatedly by the sensor until it returns True. If it returns False, the sensor will wait for a specified interval (defined by poke_interval) before checking again. This process continues until the sensor times out (defined by timeout) or the condition is met.
Benefits and Limitations¶
Benefits¶
- Highly extensible and customizable
- Excellent for orchestrating complex workflows
- Scalable to handle increasing workloads
- Strong community support
Limitations¶
- Can be complex to set up and manage
- Requires knowledge of Python for creating DAGs
- Potential performance issues with very large DAGs